
This bug in Google Search Console’s robots.txt testing tool…
Before you read, let me say I think Google should fix it as soon as possibile.
What I’m talking about? Here it is.
You all know Google Search Console offers a nice tool to test robots.txt changes. I think it’s been a great introduction, long time ago, but I’ve noticed it’s not reliable when it comes to a particular case, that’s when your URL contains characters you have to escape.
Here I need to quote a few technical passages. The first one is from Google’s webmasters guidelines for file robots.txt:
Non-7-bit ASCII characters in a path may be included as UTF-8 characters or as percent-escaped UTF-8 encoded characters per RFC 3986.
In RFC 3986 you can learn more about encoding characters and I suggest you read it entirely; what you need to know, though, is that if your URL contains any symbols not belonging to this table, it has to be percent-escaped, that means should have this syntax:
pct-encoded = “%” HEXDIG HEXDIG The uppercase hexadecimal digits ‘A’ through ‘F’ are equivalent to the lowercase digits ‘a’ through ‘f’, respectively. If two URIs differ only in the case of hexadecimal digits used in percent-encoded octets, they are equivalent. For consistency, URI producers and normalizers should use uppercase hexadecimal digits for all percent-encodings.
In paragraph 2.4 of RFC 3986 you can understand that:
For example, the octet corresponding to the tilde (“~”) character is often encoded as “%7E” by older URI processing implementations. The “%7E” can be replaced by”~” without changing its interpretation.
Maybe this starts seeming familiar to you: you have non US-ASCII characters in your URL and your server translates them in a pct-encoded value (%7E, for instance).
Now let’s say you want to block all URL containing the < (less than) symbol. You would write:
Disallow: /*%3c
You test the rule in Google Search Console, and the tool says your rule doesn’t block the files as you were expecting.
Click on images to zoom.

I asked John Mueller a few days ago on Twitter and he suggested me to double check using fetch as Google.
@JohnMu thanks, but shouldn't the tool say blocked in the screenshot? I don't like actually changing robots.txt to test via fetching tool 🙁
— Giuseppe Pastore (@Zen2Seo) 6 settembre 2016
Fetching as Google requires that you first change your actual robots.txt and then you can check if the page is blocked or not.
And of course, since the actual spider accepts ptc-encoding, the rule is correct and the page is blocked.
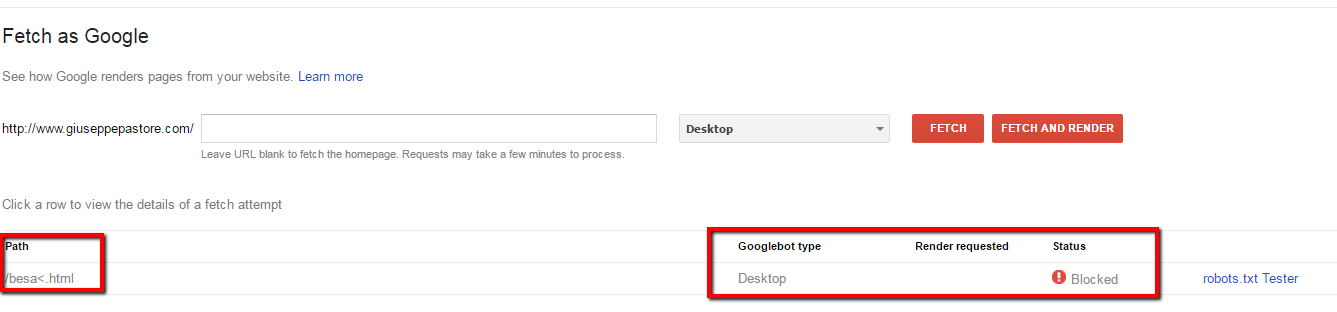
But the tool was saying Allowed…
So, when you have characters to be encoded you may:
1) use the testing tool, receive a wrong message, assume that the rule is not correct and write another one, usually more generic. This might lead you to block unwanted pages.
2) actually change robots.txt to check via fetch as Google, but this is not a safe test since you’re updating a sensible file.
In both cases, we all know messing up with file robots.txt is easy and results can be terrible.
So, what I’m asking with this post is Google to fix the robots.txt testing tool, so that one can really test disallow rules also when they contain encoded characters.
If you think like me that’s very important, help this post getting traction by sharing it and citing it wherever you can (if you use Twitter, my handle is @Zen2Seo)
2 COMMENTS
This is indeed a very dangerous bug. We should be able to rely on Google’s *official* testing tool to get things right and tell us how the robots.txt file will be handled on a live site. That’s the whole point of the testing tool!
Rolling out a potentially catastrophic change to your robots.txt file and only then be able to test it properly is not an acceptable solution. It could lead to dramatic consequences on websites, including de-indexing of entire sites or the indexing of confidential or sensitive information. The latter is especially tough to fix, as it’s notoriously hard to get a document out of Google’s index.
With all the emphasis on security from Google’s side, this is a bit of a lapse of judgement.
I definitely agree, Barry. The testing tool should let people testing in safe environment… deploying a rule to test if it’s working can be harmful if not catastrophic sometimes.