
How Title tag reverse engineering led me to a…
The first time I dealed with the problem of knowing how many words of a Title Tag Google indexes was in October 2011, when I read a detailed article by Enrico Altavilla (in Italian, but I suggest you try reading it with Google Translate). Before that day, I’m honest, I never asked myself that question since I was simply thinking in term of good practice (“keep it short”).
In his article, anyway, Enrico concluded that Google indexes only the first 12 words of a Title tag; at the time, I stored that information without trying to get more knowledge about the topic.
Now, after many months, I’ve conducted a test on my own and I’ve decided it could be interesting to discuss its results.
So, let’s start from the beginning.
Using Intitle:
I’ll start summarizing what Enrico showed in his post. Considering some documents whose Title tag was longer than twelve words (Eg. One two three for five six seven eight nine ten eleven twelve thirteen fourteen etc.), he showed he couldn’t get them as a result of a thirteen words query on Google using the intitle: operator plus quotes (I can add that you cannot get any results even using allintitle with 13 words):
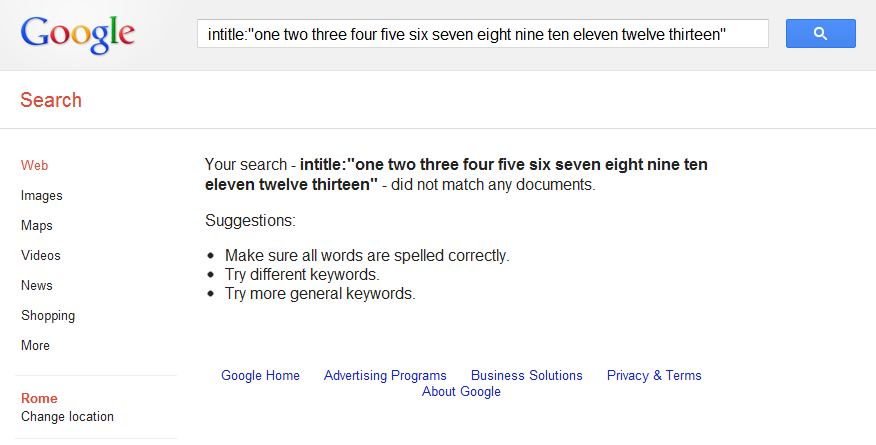
Pages, however, were returned limiting the query to the first twelve words of the Title:
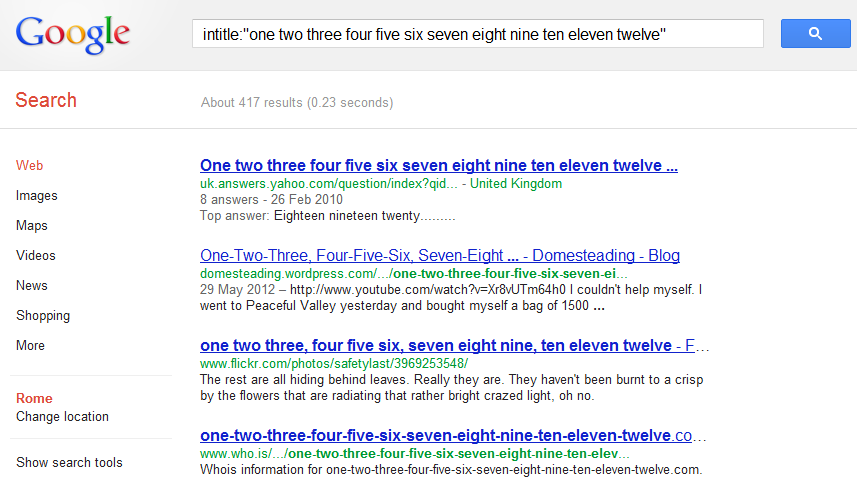
Then Enrico concluded that Google indexes only the first 12 words of the Title tag.
Was there a limit in that test? I didn’t know. Enrico didn’t use any files specifically created for the test (in which he could put some control keywords) and so his conclusions could depend on advanced operators properties. I mean: was Google indexing only 12 words in a Title tag, or was intitle: incapable of working with more than 12 words?
If you look at this screenshot you can easily know the answer:

12 words and no results, just because they’re not the first 12… it’s not a problem of how many words you use with intitle:. The problem is that intitle: works on something that can’t contain more than 12 words.
More than 12 words?
Some days ago, Darren Slatten added some informations with a post that shows how Google is actually capable of returning documents when you search for the 13th term of a Title Tag.
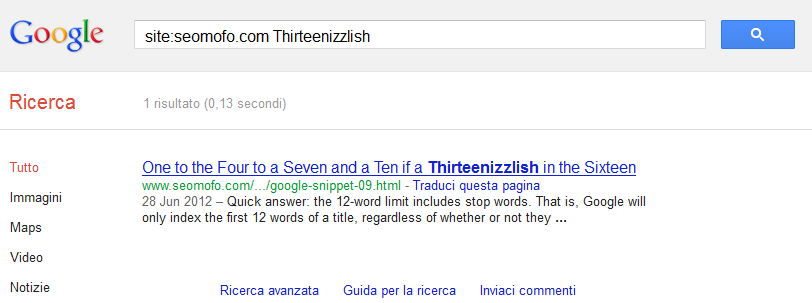
Now, does this mean that Google indexes more than 12 terms as part of Title tag?
At this point, Darren stated that:
Just Because Google displays 13 words in the title in SERP Does not Mean That document is actually getting credit for all 13 words.
This could be something to be discussed if you look at this SERP:
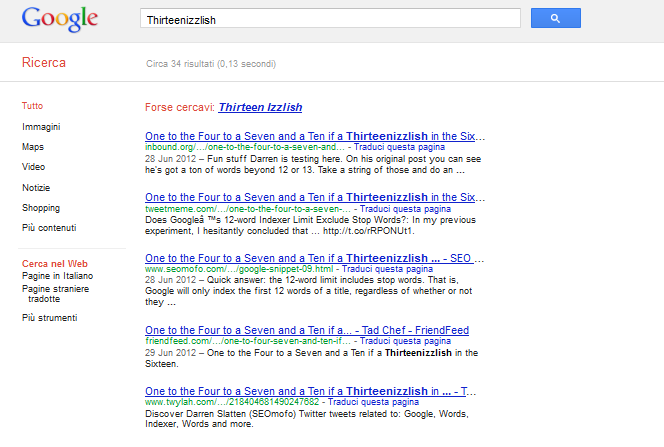
When providing results to a query, Google needs to determine the ranking of each document to produce the SERP and we can notice that the best ranking pages are those which contain the term in the Title (we all know that the presence of a term in the title weights more than if it’s placed in the body). We could conclude that the 13th word of the title is used by Google as well as the previous twelve.
But since that wasn’t a “real SERP”, it could be useful to run a new test to get some other data.
Testing a real word
In my test I don’t use an invented word, but a real one: scozzonatore. In Italian, a “scozzonatore” is someone that domesticates horses for riding (a very uncommon word, but it exists in the Italian vocabulary).
Searching for this word, Google.it returns approximately 7.470 results.

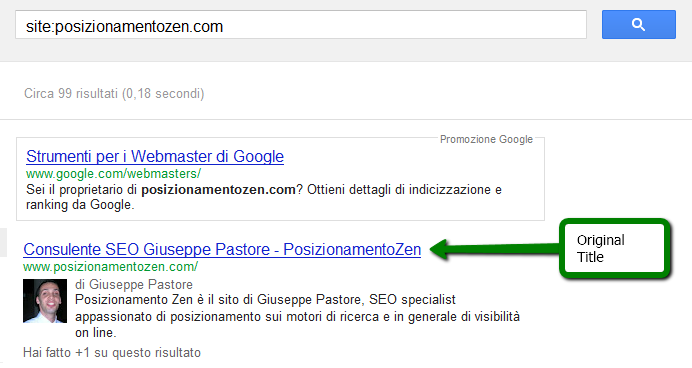
So my question is: Am I able to rank a page in this SERP using the term scozzonatore only as the thirteenth word in a Title tag? To test it I used the homepage of my Italian site.
The title of the page was originally SEO Consultant Giuseppe Pastore – PosizionamentoZen. As you can see, it didn’t contain the term before the test.
So, I simply changed the Title in:
Consulente SEO Giuseppe Pastore: posizionamento siti sui motori di ricerca consulenza SEO scozzonatore – PosizionamentoZen
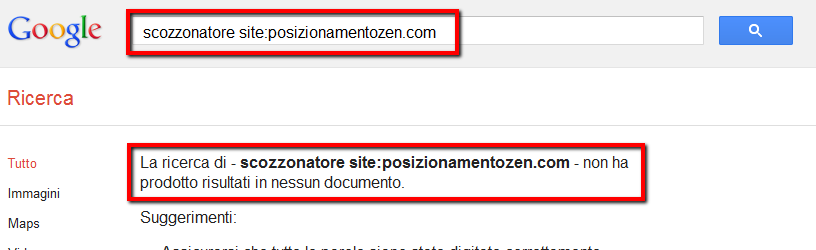
With scozzonatore as the 13th word of this title, after a few days I’ve had my homepage ranking at the 68th position for this term.
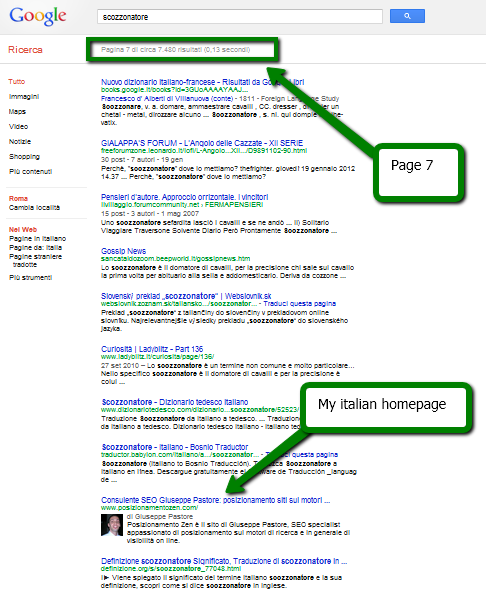
A first conclusion could be that, although its contribution is low, a word at the thirteenth place in a Title helps to rank. But I expected to rank better than 68th and I wondered if that word really belonged to the Title tag or to something else.
Keep in mind I had added the word to the Title, but whilst I can’t get any results using intitle: (you could try yourself), I can get them… using intext:!

It could seem now we have all the answers: Google indexes only 12 words as part of the Title and the rest is somehow included in the body text. But I’m not completely satisfied…
Title stored in Blocks?
Let’s come back to Enrico’article; in his post he stated that when parsing a web page, Google doesn’t store all the text as it was a sequence of words, but put it into “blocks” and this applies also to Title tag. Some special characters produce this separation. On of these is “|” (Pipe).
For example, if you look at the following two screenshot you can see I’m able to get a page of my crime novels website splitting the title:

But Google doesn’t show any results if I search for the entire title in quotes, because of the pipe:

I’ve asked myself, what if use a 50 words long Title? Does Google put it into several blocks, considering the first one (12 words) as “Title” and the rest as “text“?
This is the page I’ve used:

I’ve tried with different combinations of queries but always with the same result: no difference in treatment between the 13th and the 50th words (those belonging to “text”). So I guess there aren’t any other “blocks” for Title tag, but everything beyond the 12th word (upper limit still uncertain) goes in the same container. That is “text”.
What’s in the middle?
An easy question would now be: if those words belong to the body text, can I search for the 50th word plus the first one of the actual body text, in sequence? Being more clear: does Google put the exceeding words of a Title just before the body text?

The answer is: no. But I’m a curious guy. So look at this:

Google returns the page when I asked for a distance of 3+ words between the last one exceeding in the Title tag and the first actual one of the body text.
I’ve tested other pages with a long title and found that the more the code before the first word in the body, the more the distance you’ve to specify in your query. For this page (http://au.answers.yahoo.com/question/index?qid=20070913190510AAbq71L), for example, it’s 12 words.

I haven’t been able to surely determine what counts as a word, but in my tests it seems you can skip metatags, scripts and css.
Confirmations
Now, it’s time for some conclusions:
- Enrico Altavilla was right: Google indexes only the first 12 words as Title tag;
- Darren Slatten was partially right: you don’t get credit for the exceeding words as Title, but as they were text.
A discovery?
The most interesting part, however, is something I wasn’t looking for. Google doesn’t put the extra words of a Title just before those ones in the actual body text: code between them seems to be counted as words.
Looking at this, we should ask ourselves: does a lot of code before our text hurt our on-page optimization? It could be not only a code/text ratio problem, nor a matter of how many Kbytes the file weights. Your “text” containing unwanted and unknown stuff could be something bigger than a vague prominence concept.
Test your own ideas
Anyway, I’ll finish this post with a consideration: I’ve started a test looking for Title tag and ended up to a totally different problem.
This should suggest you not to accept what other SEOs say without doing your own tests: you could find either different or identical results, but if you don’t try there’s no chance you can find extra interesting informations.
Now, if you’ve arrived to read this final paragraph, maybe it means you liked this post. Please consider sharing it, and enjoy your reverse engineering (and if you continue my test, don’t forget a link!).
15 COMMENTS
Thanks Giuseppe for the nice article! 🙂
I completely agree about the fact that any research shouldn’t be blindly accepted by its readers but, on the contrary, it should be considered by users an encouragement to study the matter even further and an opportunity to improve their own analytical skills.
I would like to give credit to Francesco Terenzani, who was the first person to publicly show that Google indexes as “body text” the words after the 12th. 🙂
Your find about the “something” indexed between title contents and body contents is very interesting! Keep up the good work and thanks again for sharing your results.
Thanks for stopping by and commenting, Enrico, and for letting me know about Francesco tests.
I’ve tested a little with AROUND and Headings tag too, and it seems to me you can get similar results. Maybe it worths to spend some more time investigating
[…] The first time I dealed with the problem of knowing how many words of a Title Tag Google indexes was in October 2011, when I … […]
[…] Google indexes 12 words of a Title but I discovered something new – … 1 Upvotes Discuss Flag Submitted 1 min ago Aleyda Solís SEO en.posizionamentozen.com Comments […]
Wow that’s a really different ending to what I was expecting.
Hugely interesting post, especially the Pipe and the code length affecting potential optimisation.
Thanks for posting this Giuseppe, I think we’re going to see a lot more on this topic over the next few months. Excited to see the whole industry get involved with the experiments and see how this progresses,
Thanks again Giuseppe!
-Matt-
Thanks for reading, Matt.
I think it worths investigating more and I’ll be happy to read of other tests about this 🙂
Thanks a lot Giuseppe,
Didn’t know about this till this date! Interesting Engineering!
have a look at here to draw conclusions
http://www.seomofo.com/experiments/serp/google-snippet-07.html
Cheers Giuseppe, nicely done Sir! As Matt mentioned, bet there are more folks testing different variations right now. Awesome community!
Interesting and off to do some tests 😛 Is a shame there doesn’t appear to be any more ‘blocks’ after the first 12 words. I had alsorts of crazy ideas with that and the “|” character 😛
Thanks for doing all that experimentation, Giuseppe. Very interesting. Could you please clarify this idea:
“I’ve tested other pages with a long title and found that the more the code before the first word in the body, the more the distance you’ve to specify in your query. For this page (au.answers.yahoo.com/question/index?qid=20070913190510AAbq71L), for example, it’s 12 words.”
What would be an example of code preceding body text: an image? CSS?
Would it be more search-friendly for the average user if the website admin limits any code between the title and first word of body text on a page or post?
Thanks.
Hi Emily,
thanks for your comment. For that page I found the minimum distance is AROUND(12) but as I was writing I haven’t been able – testing different pages – to understand what counts and what doesn’t.
In my opinion link, script, meta don’t count, whilst div, a, ul etc probably do. It’s just an hypothesis, however.
The most of the HTML code anyway depends on the template and not on the actual text formatting, so this suggests to keep content as close as possible to (a good practice we already knew). The interesting part will trying to understand what Google actually saves as “text” and why…
Focusing on characters more than in terms of words would be more relevant…
Killer article – I always had thought Google was takings in account more than we thought but I was more thinking in terms of Characters and not words. Thanks for the eye opener
[…] indicizzate come title, la parte restante era comunque indicizzata come se fosse corpo del body: http://en.posizionamentozen.com/blog…e-my-seo-test/ Spero d'essere stato utile MODPosizionamento nei motori di ricerca Federico Sasso, autore del […]